Building FinRAGify- An End-to-End Earnings Call Research ChatBot using RAG with LLMs
Checkout the deployed app in action: http://ec2-40-177-46-181.ca-west-1.compute.amazonaws.com:8501
The link to the github repo for this app is here. Please check the readme in this repository for deployment instructions of this app.
Motivation
As a retail investor, I often needed quick answers from quarterly earnings calls for my long-term stock investments without spending hours listening to them. With the advent of Large Language Models (LLMs), I saw an opportunity to build a tool that could regularly track my investments with ease.
One feature I was particularly excited to build was the management consistency analysis. In investing, a key principle is that good stock performance stems from good business performance, which in turn requires competent management that sets realistic expectations and meets them consistently. While this feature isn’t perfect, it addresses this crucial aspect to a reasonable extent.
This blog outlines the proof-of-concept app development of FinRAGify and how it leverages advanced NLP technologies like Retrieval-Augmented Generation (RAG), LangChain, and OpenAI’s GPT-4 mini to streamline financial analysis, offering both a standard version using a Cross Encoder Model from Hugging Face and a lightweight version utilizing Cohere’s Reranking API.
The Problem Statement
Reviewing quarterly earnings for multiple companies is a daunting task, whether you’re a financial analyst or a retail investor. Manually extracting key insights and assessing management’s consistency over time is time-consuming and prone to error.
FinRAGify automates this process, allowing both analysts and retail investors to focus on decision-making rather than data gathering. By leveraging advanced NLP techniques, FinRAGify analyzes, ranks, and retrieves relevant information from large datasets (8 quarters of earning’s call transcripts ~ 65k words), ensuring precise and contextually accurate answers—making it easier to keep track of long-term investments. The management consistency feature, in particular, helps assess whether a company’s leadership is consistently meeting the expectations they set, which is critical for long-term investment success.

Technical Overview
FinRAGify is built using the following technologies:
- LangChain: A framework for building language model applications, enabling seamless integration of various NLP components.
- OpenAI GPT-4 mini: A language model that powers the app’s natural language understanding and generation.
- FAISS (Facebook AI Similarity Search) Vector Database: A vector database used to store and retrieve embeddings, allowing for rapid and relevant searches.
- Streamlit: A framework for building and deploying the app with a user-friendly interface.
- FinancialModelingPrep API: Used to gather the quarterly earning’s call transcript data, ensuring up-to-date and reliable financial information.
- Reranking Mechanism: A reranking mechanism, which uses either a pre-trained CrossEncoder model from Hugging Face in the regular version or a reranking API (Cohere) in the lightweight version, to rerank and extract a smaller subset of chunks from those returned by the retriever.
Two Versions of FinRAGify
1. Regular Version:
- Uses an open-source cross encoder model from Hugging Face, a leading platform providing pre-trained models. This version reranks retrieved documents and requires about 300-600 MB of RAM.
- The Cross Encoder model, specifically ms-marco-MiniLM-L-6-v2, is pre-trained on a dataset of 3.2 million documents and 367,013 queries, it effectively identifies the most pertinent information, making it highly accurate for ranking purposes.
2. Lightweight Version:
- Utilizes Cohere’s Reranki API, for document reranking, significantly reducing the RAM requirement to 150-300 MB.
- This version is optimal for deployment in environments with limited resources (e.g. free tier AWS EC2 t3.micro instance), offering a balance between performance and efficiency.
What is Retrieval-Augmented Generation (RAG) Technology?
Retrieval-Augmented Generation (RAG) combines information retrieval with natural language generation to improve the accuracy and relevance of AI-generated responses. In FinRAGify, RAG enhances the language model by grounding its answers in specific, relevant data from earnings call transcripts.
How RAG Works in FinRAGify:
-
Information Retrieval: When a user asks a question, FinRAGify retrieves the most relevant chunks of earnings call transcripts from the FAISS vector database based on the similarity to the query.
-
Contextual Generation: These retrieved chunks are provided as context to the language model (GPT-4 mini), which then generates a concise and accurate response.
RAG ensures that FinRAGify delivers detailed, contextually accurate insights, crucial for financial analysis where precision is paramount.
Data Ingestion System: Loading, Text Splitting and Vector Storage
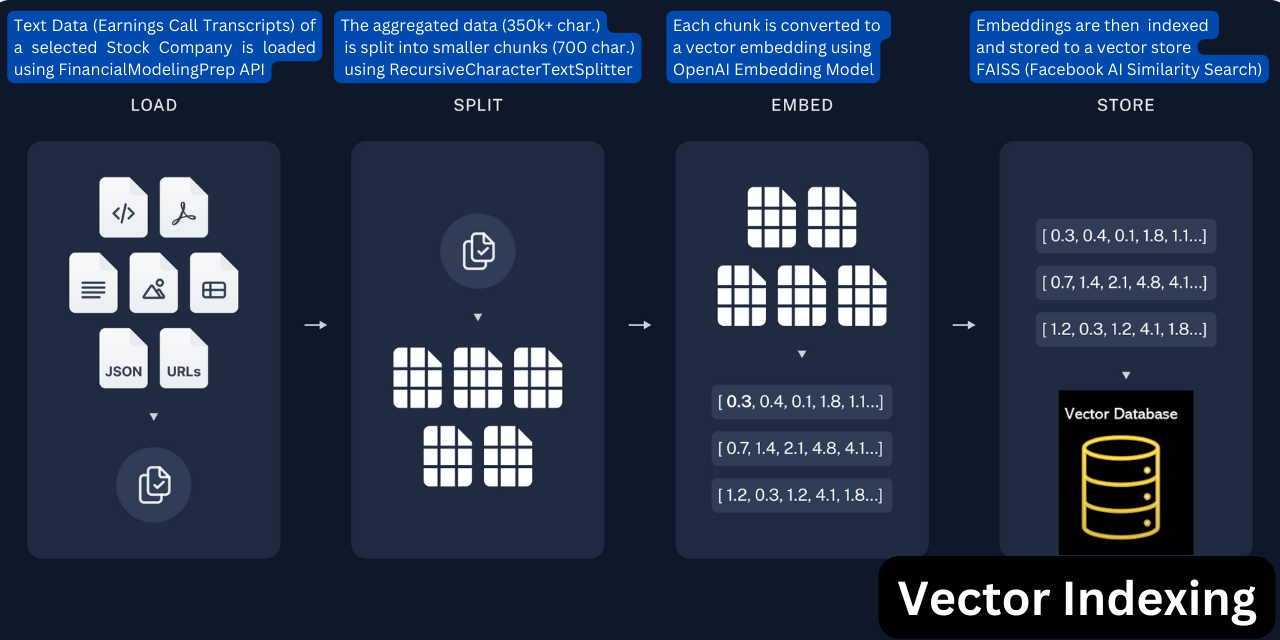
Loading the Data:
FinRAGify pulls 8 quarters of earnings call transcript data via the FinancialModelingPrep API, a reliable source trusted by many major providers. The aggregated data, which can contain upwards of 350,000 characters (~ 65k words), is then recursively split into chunks with a maximum size of 700 characters (~ 130 words) using the Recursive Character Text Splitter. The Recursive Character Text Splitter tries to split the text by different characters to achieve the desired chunk size. By default, it attempts to split by the following characters in order: ["\n\n", "\n", " ", ""]. If the first character does not yield a chunk of the desired size, the splitter moves on to the next, and so forth, until it finds a suitable split.
An overlap of 100 characters (~ 18 words) is chosen to retain some context from the previous chunk. This overlap ensures that the transition between chunks is smooth, preserving the continuity of information and improving the relevance of the retrieved chunks during later stages of processing. The code snippet is provided below:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=700,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.create_documents(transcript_contents, metadatas=transcript_metadata)The Recursive Character Text Splitter ensures that each chunk is within a specified size limit, preventing large blocks of text from overwhelming the model. This process is essential for creating structured data that can be fed into the model efficiently. The create_documents function then converts these chunks into LangChain document types, attaching relevant metadata like the date, year, and quarter of the earnings call.
These documents are then embedded using OpenAI Embeddings, and stored in a FAISS (Facebook AI Similarity Search) vector store. FAISS allows for quick similarity searches, making it easier to retrieve relevant transcript chunks when a question is asked.
embeddings = OpenAIEmbeddings()
vectorstore_openai = FAISS.from_documents(docs, embeddings)How FinRAGify ‘Answers’: Retrieval, Reranking, and Generation
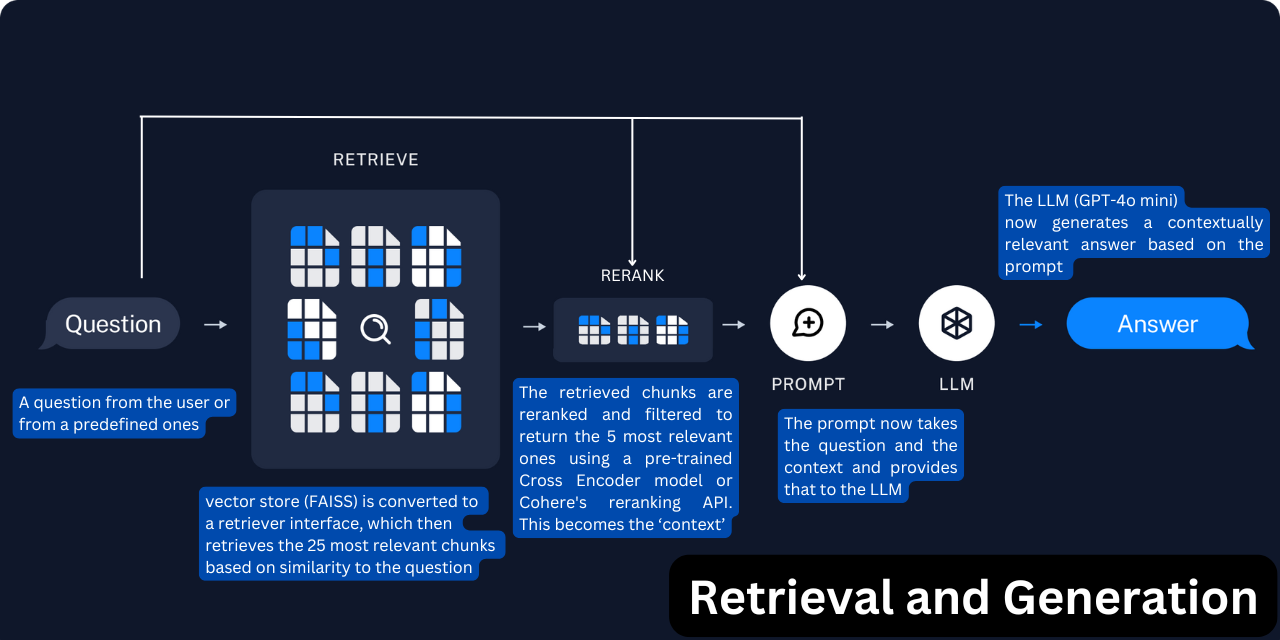
Prompt Template and Document Retrieval
The heart of FinRAGify lies in how it retrieves and processes data to generate insightful answers. The get_answers function is pivotal in this process:
prompt_template = """You are a financial analyst. Using the following context from earnings call transcripts, answer the question below. Each paragraph includes details about the quarter and year, which helps establish the chronological order of the information.
Keep your answer concise, under 200 words.
Context: {context}
Question: {question}
Answer:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain = prompt | chatLLM | StrOutputParser()Prompt Template: This template assigns a specific role—here, that of a financial analyst—to focus the language model’s responses on financial analysis. It handles custom questions that may not directly relate to company performance by ensuring that the context provided is relevant and concise.
- Context: Pulled from the data stored in the vector database, where the transcripts were broken into 700-character chunks.
- Question: The user’s query that triggered the retrieval of these chunks.
The retrieval process begins with the FAISS similarity search:
retriever = vectorstore_openai.as_retriever(search_kwargs={"k": 25})
docs = retriever.invoke(question)Here, k=25 specifies the number of chunks retrieved based on similarity to the question. These chunks are then reranked using the Cross Encoder model, with the top 5 most relevant chunks provided to the LLM for final analysis.
Reranking: Why Use a Cross Encoder?
The cross encoder model (ms-marco-MiniLM-L-6-v2) is particularly suited for this application because it evaluates pairs of text (the question and each chunk) to determine relevance, making it more accurate for ranking purposes. Pre-trained on a dataset of 3.2 million documents and 367,013 queries, it effectively identifies the most pertinent information, making it highly accurate for ranking purposes.
Ensuring Management Consistency: The check_management_consistency Function
Similar to the get_answers function, the check_management_consistency function evaluates how consistent a company’s management has been in delivering on their promises. This function uses a fixed question within the prompt template, which is specifically designed to check for consistency over multiple quarters.
retriever_search_qs = """What were the specific targets, deadlines, or expectations—such as those to be met by a certain quarter—in areas of product launches, strategic initiatives, cost-cutting measures, growth in new markets, share buybacks etc., that the management set to deliver on future quarters, and have they delivered on them?"""Fine-tuning the Retriever Prompt: By fine-tuning the prompt provided to the retriever (e.g., removing the word “outlook”), the quality of retrieved chunks can be significantly improved, leading to more relevant responses and higher retrieval accuracy.
Prompt A: “Review and summarize the company’s planned initiatives and outlook for the upcoming quarters, focusing on strategic goals and future developments, for example, in areas of new markets, new products, new services, share buybacks.”

The figure above shows the chunks returned with Prompt A i.e. without fine-tuning. It can be seen from this that 3 of the chunks are just disclaimers without any relevant information specific to the question.
Prompt B (fine-tuned): “Review and summarize the company’s planned initiatives for the upcoming quarters, focusing on strategic goals and future developments, for example, in areas of new markets, new products, new services, share buybacks.”
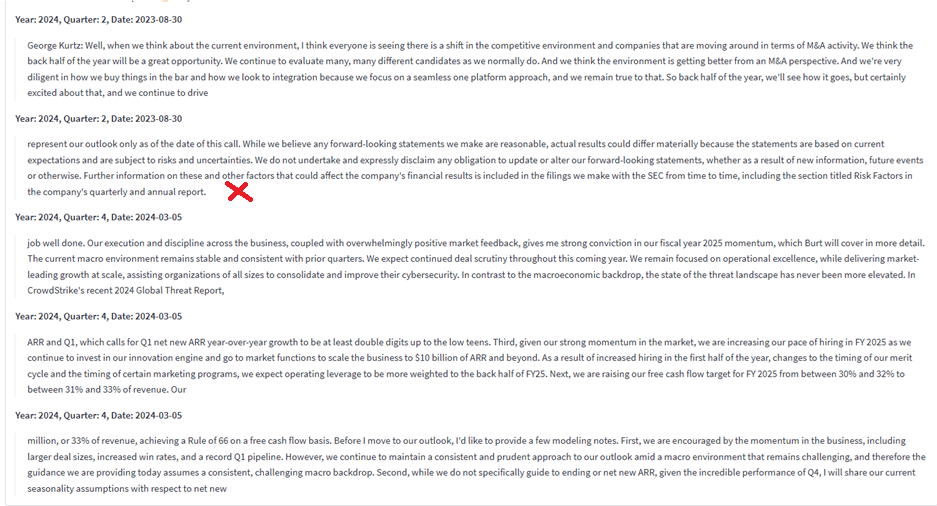
The figure above shows the chunks returned with Prompt B (i.e. fine-tuned by removing ‘outlook’). It is evident that only one of the chunks lacks relevant information specific to the question. Simple fine-tuning of the retriever query can significantly improve retrieval accuracy with minimal effort.
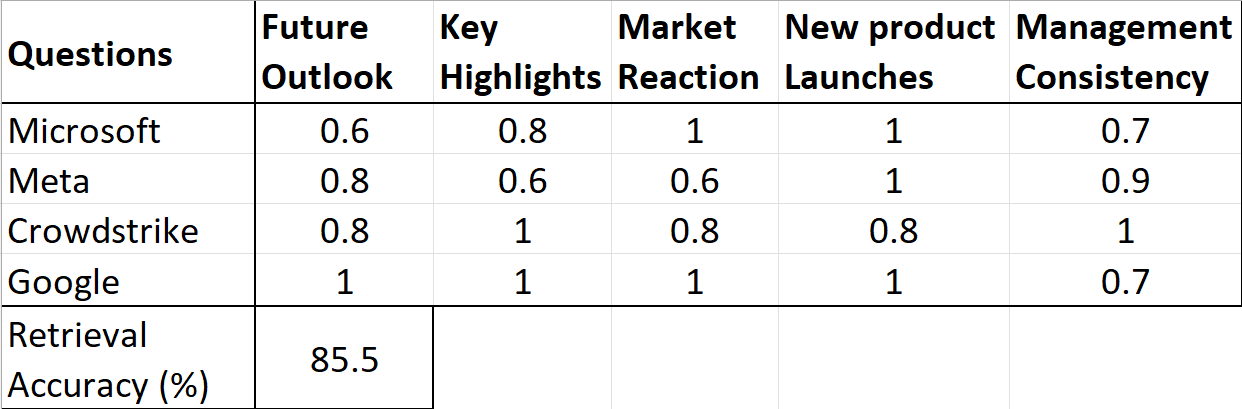
Retrieval Accuracy: This is calculated as the ratio of relevant chunks retrieved to the total chunks retrieved. By iteratively fine-tuning prompts and by adding a reranking mechanism, we achieved an average retrieval accuracy of 85.5% for various pre-set questions (‘What are the key highlights?’ etc.) across 4 different stocks (Microsoft, Meta, Crowdstrike, and Google).
Conclusion
FinRAGify represents a creative demonstration of how AI (RAG Technology) can be used to streamline investment research. By incorporating both regular and lightweight versions, the tool offers flexibility in resource usage while maintaining high accuracy in financial analysis.
Whether you’re an analyst or a retail investor, FinRAGify simplifies the process of extracting key insights from earnings call transcripts, saving time and enhancing decision-making. The tool’s unique management consistency feature ensures that users can assess whether company leadership consistently meets their expectations—a crucial factor for long-term investment success.
Explore the code and learn more about FinRAGify on GitHub. Feel free to reach out with any questions or suggestions or contributions. Let’s advance financial analysis together with AI!